Is My Website Traffic Real or Bots? (2026 Data)
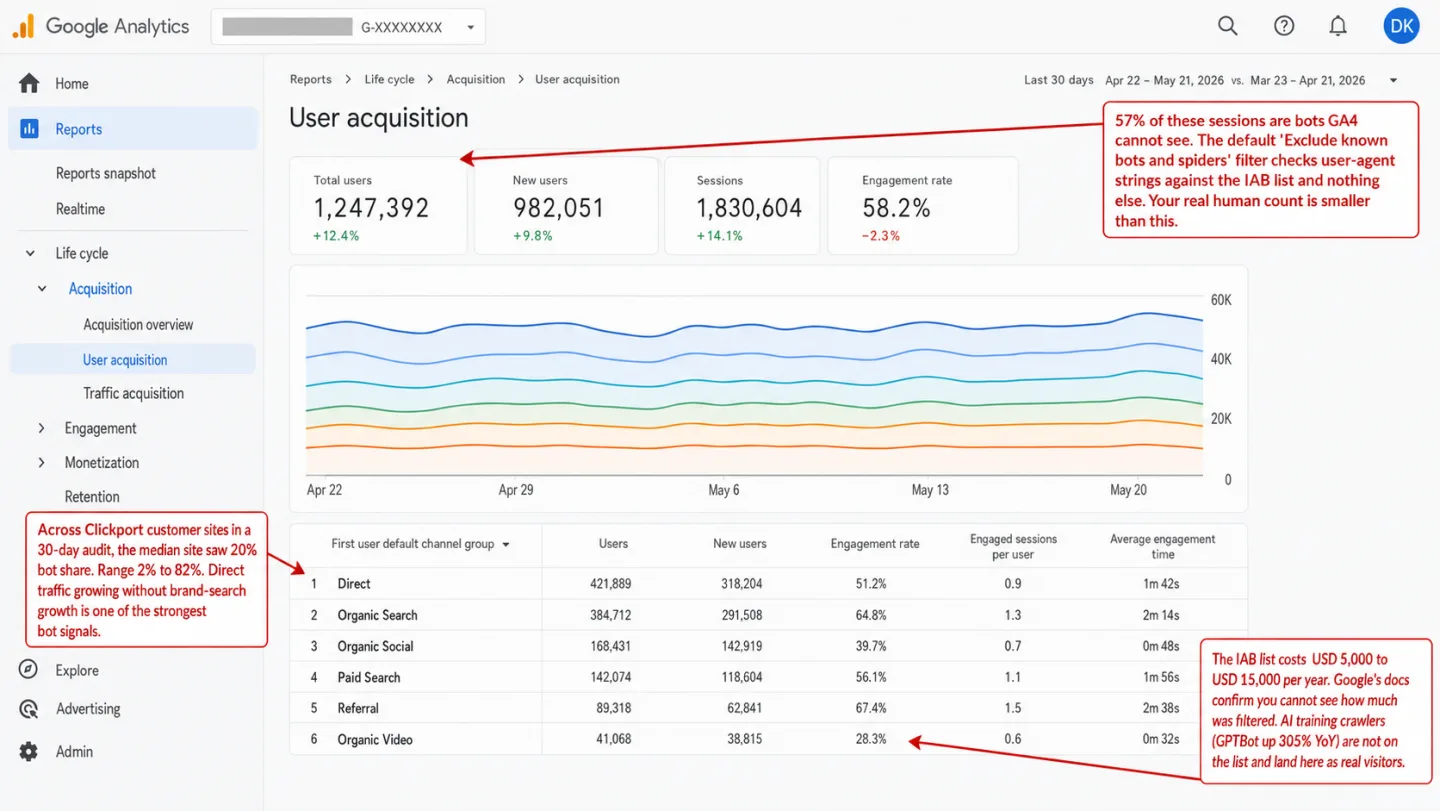
Is my website traffic real or bots? Some of it is bots, more than your dashboard admits. Over 30 days in April 2026, across the sites we measure, the median site saw 20% of incoming traffic flagged as bots. The range ran from 2% to 82%. And 57% of those bots would have sailed straight through GA4's default "Exclude known bots" filter, because catching them needed signals GA4 never checks. Put another way: if you run GA4, more than half the bots on your site are invisible to it. Here is the full picture.
- Across the sites we measure, over 30 days the median site saw 20% of incoming traffic flagged as bots. The range ran from 2% to 82%. Bot load varies wildly by site type, content, and whether you're being actively targeted.
- GA4's 'Exclude known bots and spiders' filter is always on and uses the IAB/ABC International Spiders and Bots List. Access to the list costs between $5,000 and $15,000 per year. It matches user-agent strings. It doesn't check browser fingerprints, datacenter IP reputation, or behavioral signals.
- When we measured our own bot detections, 57% of bots we caught relied on non-UA signals: browser GPU fingerprinting, datacenter IP reputation, and behavioral velocity. Those bots pass through GA4's filter undetected.
- AI training crawlers including GPTBot, ClaudeBot, Applebot-Extended, and Meta-ExternalAgent aren't on the IAB bot list. GA4 counts them as real visitors. GPTBot's requests to sites grew 305% year-over-year per Cloudflare Radar.
- Ad platforms refund billing on invalid traffic they detect but don't notify your analytics tool. A bot that clicked your Google Ad still lands in GA4 as a real session. Lunio's 2026 data shows IVT rates by platform: TikTok 24.2%, LinkedIn 19.9%, Google 7.6%.
How much of my traffic is bots?
It depends on your site. But it's almost certainly more than your analytics says. Across the sites Clickport measures in the 30-day window, the median site had 20% bot share. One clean B2B SaaS site sat at 2.5%. One site under an active scraping campaign hit 82%. The spread is the answer, not the average.
The big industry reports tell the same story at scale. Imperva's 2025 Bad Bot Report looked at 13 trillion blocked requests across 2024 traffic. It found 51% of all web traffic was automated, and 37% was bad bots. That means machines beat people on Imperva's network for the first time in a decade. Akamai's June 2024 State of the Internet report put bots at 42% of web traffic, two-thirds of it malicious. Fastly's Q1 2025 Threat Insights came in at 37% bots, and 89% of that was unwanted. Three networks, three methods, same direction. In plain English: the infrastructure-level number isn't really in dispute, and about half the web is machines.
So at the infrastructure layer, somewhere between 40% and 50% of requests aren't human. At the site level the range gets wider. A quiet SaaS portal and a scraped ecommerce catalog sit at opposite ends of the same line. The bot traffic problem isn't a number you can quote. It's a range. What lands you on it is what you publish, who's scraping it, and what your analytics can see.
Look at what that spread does to your numbers. If your bot share is 2%, your GA4 numbers are close to right. If it's 20%, every trend line on your dashboard is off by a fifth. If it's 80%, you're not measuring your audience anymore. In plain English: you're measuring a scraper's schedule.
Why GA4 says your traffic is clean when it isn't
GA4's "Exclude known bots and spiders" filter is always on. You can't turn it off. That sounds reassuring until you read how it works. Per Google's documentation, GA4 filters using "a combination of Google research and the International Spiders and Bots List, maintained by the Interactive Advertising Bureau."
Two things about that list most people never hear. Both change how far you can trust it.
First, it's not free. The IAB/ABC International Spiders and Bots List costs $5,000 a year for IAB members, $7,500 for associate members, and $15,000 a year if you're not a member. That means the list you're trusting can cost more than a small analytics budget. You get it by FTP after you subscribe. You can't browse what's on it. You can't see what GA4 caught with it. Google tells you it's working, and you take that on faith.
Second, the list matches on user-agent strings. A bot that sends Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0 Safari/537.36 walks right through. Not because it's human. Because the list is hunting for strings like Googlebot, Applebot, YandexBot. A scraper that calls itself Chrome gives the list nothing to grab.
When I looked at 30 days of our own detections, UA patterns caught 43% of the bots. The other 57% needed signals GA4's filter can't see: browser GPU fingerprinting, datacenter IP reputation, behavioral velocity. That means GA4's one check would miss most of what I flagged. An independent controlled test in 2024 pointed three different bot setups at a GA4 property and found it let bot traffic through in every one. Which means the filter is on. It's just looking in the wrong place.
GA4 also won't tell you what it filtered. Google's own documentation says it plainly: "you can't see how much known bot traffic was excluded." The data is dropped before processing. No bot report, no BigQuery export, no audit trail. You're trusting a filter you can't inspect, fed by a list you can't read.
I ran the same test against our own tracker earlier and reached the same conclusion from a different angle. Anything above a UA-match layer has to come from somewhere else.
The three bot categories GA4 can't see
The bots that slip past GA4's filter fall into three groups. Each one breaks a different assumption the IAB-list approach is built on.
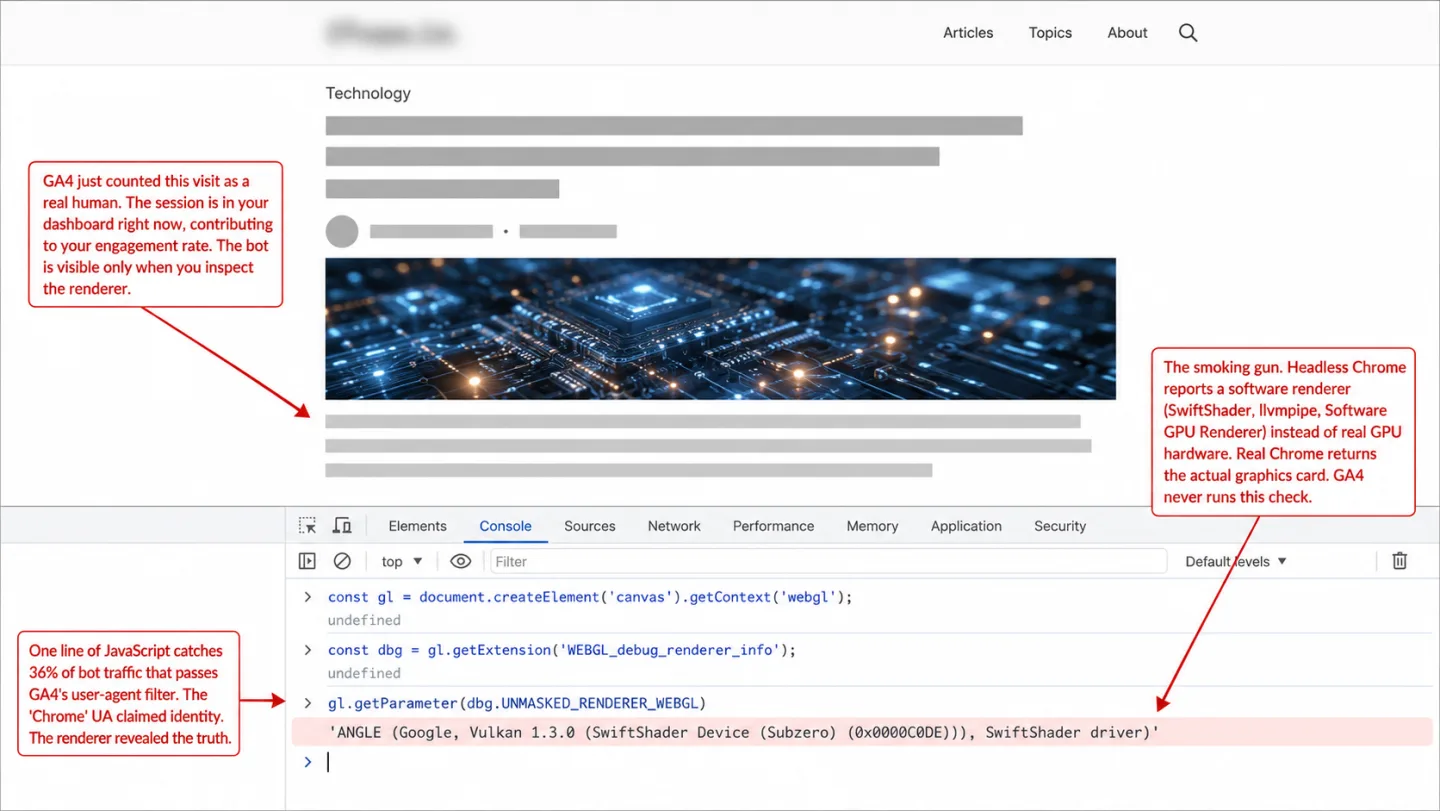
Headless browsers running real JavaScript. Puppeteer, Playwright, Selenium, and stealth-patched Chromium all run a real rendering engine. Your GA4 tag fires, the session gets recorded, and the UA string says "Chrome." What gives them away is what that rendering engine admits to. Headless Chrome without hardware acceleration reports renderer strings like "Software GPU Renderer" and ANGLE SwiftShader through WebGL.getParameter(RENDERER). Real Chrome reports your actual graphics card. It's a one-line JavaScript check, and GA4 never runs it. In our data, that GPU renderer fingerprint (Software GPU Renderer, ANGLE SwiftShader, and similar software-rendering strings) flagged 1.54 million bot sessions over 30 days. One signal, 36% of all the bots we caught. That means a single line of JavaScript found more than a third of them, and GA4 runs none of it.
Residential proxy bots. Services like Bright Data, IPRoyal, and Smartproxy rent out pools of real consumer IPs, often without the homeowner's say-so. A bot running through a residential proxy has the same kind of IP address as a real person on their home broadband. IP blocklists and datacenter-range filters can't tell them apart. Imperva's 2025 report found that 21% of bot attacks coming through ISPs ran on residential proxies. In plain English: one in five bot attacks now hides inside ordinary home broadband. That's exactly how the Perplexity vs Amazon fight played out in late 2025. Amazon blocked Perplexity's declared IPs, and within 24 hours Perplexity's Comet agent switched ASNs and spoofed a Chrome-on-macOS user-agent.
AI training crawlers. GPTBot, ClaudeBot, Applebot-Extended, Meta-ExternalAgent, PerplexityBot. None of them were on the IAB list the last time it synced. GA4 counts every single one as a real visitor. I'll get to the scale of this group in its own section. The mechanism is the same as the other two: the list hasn't caught up.
Our bot-detection framework walks through the technical stack behind each of these layers. The point for this article is simpler than that. A filter that only reads user-agent strings misses two kinds of bot at once: the declared scrapers that tell the truth about who they are, and the ones that lie well enough to pass for human. It catches the careless and waves through the ones that announce themselves and the ones that disguise themselves.
Signs your traffic isn't real, that you can check right now
You don't need a new tool to check. GA4 won't point at bots for you, but it will show you the marks they leave behind if you know where to look. Here's the checklist I run in the next 15 minutes.
Your Direct channel is growing with no brand activity. Direct traffic should roughly track your brand search. So if your Direct bucket jumped 30% last quarter while your branded queries in Search Console stayed flat, something else is showing up with no referrer attached. Some of it is dark social: links pasted into Slack, WhatsApp, iMessage. Some of it is bots that stripped the referrer. I dug into this exact pattern when I wrote about sudden direct-traffic spikes.
Bounce rate is near 100% on a specific source. People don't bounce 100% of the time off a real source. So when Facebook Ads sends you traffic that bounces at 98%, the problem isn't your landing page. The traffic never landed on a human in the first place.
Session duration is under 1 second for a cluster of sessions. A person needs longer than a second to decide they hate your page. A bot can load, run, and leave in under 500 milliseconds. Filter your Explorations to sessions under 1 second and look at the source they came from.
Traffic from countries you don't serve. A B2B SaaS that sells to North America and somehow gets 40% of its traffic from Vietnam, Singapore, and Brazil didn't stumble into those markets. That's bot traffic or datacenter testing, not buyers.
Same device, same screen size, same browser version, all at once. People have messy fingerprints. Bot farms don't. So if 8,000 sessions in one hour all report 1920x1080, Chrome 142, Windows 10, same country, you're not looking at 8,000 visitors. You're looking at one bot farm running 8,000 workers.
Impossible engagement ratios. Scroll depth and time on page should move together. A session with 1 second of duration and 95% scroll depth is lying about one of those two numbers. You can build that filter by hand in GA4 Explorations.
None of these proves anything on its own. But two or three of them stacking up on the same slice of traffic is a strong sign that slice isn't human.
The 2024-2026 bot case files
"Bot traffic exists" stays abstract until you see what a real campaign looks like. I pulled four documented ones from the last two years, from an AI crawler tripping over its own bug to a fight that ended in federal court.
Read the Docs, May 2024. An AI training crawler with a bug kept downloading the same zipped HTML snapshots over and over instead of caching them. 30 MB every second, around the clock, for a month. That's 73 TB in total, and nearly 10 TB in a single day. That means one buggy crawler moved more data than most sites serve in a year. The bill to Read the Docs came to over $5,000 in CDN bandwidth. An old redirect pointed to a dynamic URL that couldn't be cached. The crawler never noticed it was paying for the same file again and again.
Nerd Crawler, May 2024. A small comic-art marketplace found that ByteDance's Bytespider was firing 300,000 image requests a day, ignoring robots.txt, and rotating IPs through China, Singapore, and AWS. Bandwidth was the site's single biggest operating cost. Blocking Bytespider cut bandwidth by roughly 60% and, by the owner's own estimate, took 20-30% off the total cost of running the place. That means one bot was the site's single biggest line item.
Perplexity vs Amazon, August 2025 to March 2026. Amazon blocked Perplexity's declared PerplexityBot IP ranges on August 19, 2025. Within 24 hours, Perplexity's Comet agent switched ASNs and spoofed a Chrome-on-macOS user-agent to get around the block. Amazon had to run a forensic analysis on browser fingerprint patterns to pin the bot back down. The case ended in a federal court order in March 2026.
DataDome review platform, March 2026. A coordinated scraping operation used 855,000 unique IP addresses over 13 days to scrape a business review platform. At peak it threw 1.35 million blocked requests every two hours. The total reached 80 million blocked requests. In plain English: no IP blocklist stops an attack spread across 855,000 addresses. The point was simple: harvest the proprietary business listings in bulk.
There's a through-line here. A modern bot campaign doesn't look like the bot most people picture. It runs a real browser stack, rotates real-looking IPs, and spoofs its UA string the moment it gets blocked. A UA-list filter catches none of that.
AI crawlers, the category that didn't exist three years ago
Before 2022, "AI crawler" wasn't even a category. In 2026 it's 4.2% of global HTML requests per Cloudflare Radar. So one in every 24 page requests on the web is an AI bot, and not one of the major ones is on the IAB list GA4 uses. That means your analytics waves every one through as a person.
Cloudflare's tracking between May 2024 and May 2025 shows how fast this got big:
- GPTBot (OpenAI): raw requests grew 305% year over year, and its share of AI crawler traffic climbed from 5% to 30%. It's now the AI crawler people block first, named in robots.txt on 312 of 3,816 sampled domains.
- ClaudeBot (Anthropic): 21% of AI crawler traffic. It takes far more than it gives, crawling at a heavy multiple of the referrals it sends back, per Cloudflare's AI crawler analysis. Anthropic publishes no IP ranges to verify against.
- PerplexityBot: just 0.2% of crawler traffic, but raw requests grew 157,490% in 12 months. Cloudflare has documented Perplexity ignoring robots.txt.
- Applebot-Extended: launched June 2024 to train Apple Intelligence. It honors a robots.txt opt-out, but through a separate user-agent most publishers don't know exists.
- Meta-ExternalAgent: near-zero in May 2024, up to a 19% share by May 2025. Fastly reports Meta accounts for 52% of AI crawler traffic hitting high-authority domains.
- Bytespider (ByteDance): dropped from a 42% share of AI crawler traffic to 7% in 12 months, most likely because it's now the most blocked AI crawler on every monitoring network there is.
Fastly put it best in a 2025 analysis, under a heading that reads "Robots.txt: A Suggestion, Not a Shield." Most AI crawlers honor it. PerplexityBot has been caught ignoring it. ClaudeBot honors it but won't publish IP ranges, so you can't catch a spoofer by reverse DNS. And all of them sail past GA4's IAB-list filter for the same dull reason: none of them are on the list.
What this means in practice is plain. If you publish anything, your pageview count is padded by AI crawlers pulling your pages into their training data. GA4 tells you nothing about it.
Ad platform bot traffic, the IVT blind spot
Every big ad platform strips some invalid traffic out of your billing. None of them tells your analytics they did it. So a bot that clicked your Facebook Ad still shows up in GA4 as a real session. It pads your visitor count and drags your conversion rate down with it.
The benchmarks for invalid traffic on ad networks are specific enough to quote. Pixalate's Q3 2024 Global IVT Benchmarks covered 100 billion programmatic impressions and reported:
- Web programmatic: 14% IVT worldwide, 17% in the US and Canada
- Mobile apps: 23%, up 30% year over year
- CTV: 23%, up 44% year over year
- Safari desktop: 30% IVT, against 13% for Chrome
Lunio's 2026 IVT report leans on 2.7 billion clicks across unprotected monitor-only campaigns and splits it out by ad platform:
DoubleVerify's 2024 Global Insights reported General Invalid Traffic jumped 86% year over year in the back half of 2024. It crossed 2 billion invalid ad requests a month for the first time in Q4 2024, and 16% of that came from AI scrapers. In plain English: one in six invalid ad requests is now an AI scraper.
The money behind this is large. Global losses to ad fraud hit $37.7 billion in 2024 per Spider Labs. A separate Lunio analysis put the IVT losses across digital advertising even higher, at $63 billion in 2025.
Here's the part the platforms don't put in the pitch. Their IVT filtering only touches billing. Google Ads refunds you for the clicks it catches as invalid. Meta and TikTok have their own refund windows. But the bot still landed on your site. The session still fired your GA4 tag. The bounce still counts against your campaign. Your analytics never hears that the click got refunded, so the bottom of your conversion-rate math stays inflated. I covered the Meta version of this in more depth.
So you can get your money back on the wasted spend and still have your dashboard lying to you about how the campaign did. That means your refund and your reporting disagree, and only one of the two ever reaches your analytics.
How to diagnose bot contamination without adding any new tool
If you're not ready to switch analytics, you can still get a rough read on your bot share from what you already have. It won't be precise. But it'll point you the right way, and I'd rather you had a direction than a blank.
Step 1: Check your Direct share over 12 months. Go to Acquisition → Traffic acquisition in GA4 and set the comparison to the previous 12 months. If your Direct share grew more than 10 percentage points with no brand-marketing push behind it, that growth is suspect. Some is dark social. Some is bots that stripped the referrer.
Step 2: Check your mobile vs desktop split. Real human traffic runs 55-65% mobile in most markets, per Statcounter's monthly GlobalStats. So if your mobile share is under 35%, one of two things is true. Either you sell to a desktop-heavy B2B crowd, which happens, or datacenter bots have padded your desktop number. The size of the skew tells you which.
Step 3: Filter sessions to under 2 seconds. Build a custom Exploration for session duration under 2 seconds. Where do those sessions come from? How does the count compare to sessions over 30 seconds? A big gap means bot traffic piled up in one source.
Step 4: Cross-reference Direct growth against Search Console branded impressions. In Search Console, filter to branded queries over 12 months. If branded search is flat while Direct keeps climbing, that climb isn't real interest. It's something else.
The calculator below turns those signals into a rough estimate. I tuned it on the same numbers I watch every day.
I built the estimator as a way to think, not a verdict. The real share on your site comes down to your content, how visible you're in search, whether someone's actively scraping you, and who your audience is.
What actually works: multi-layer detection
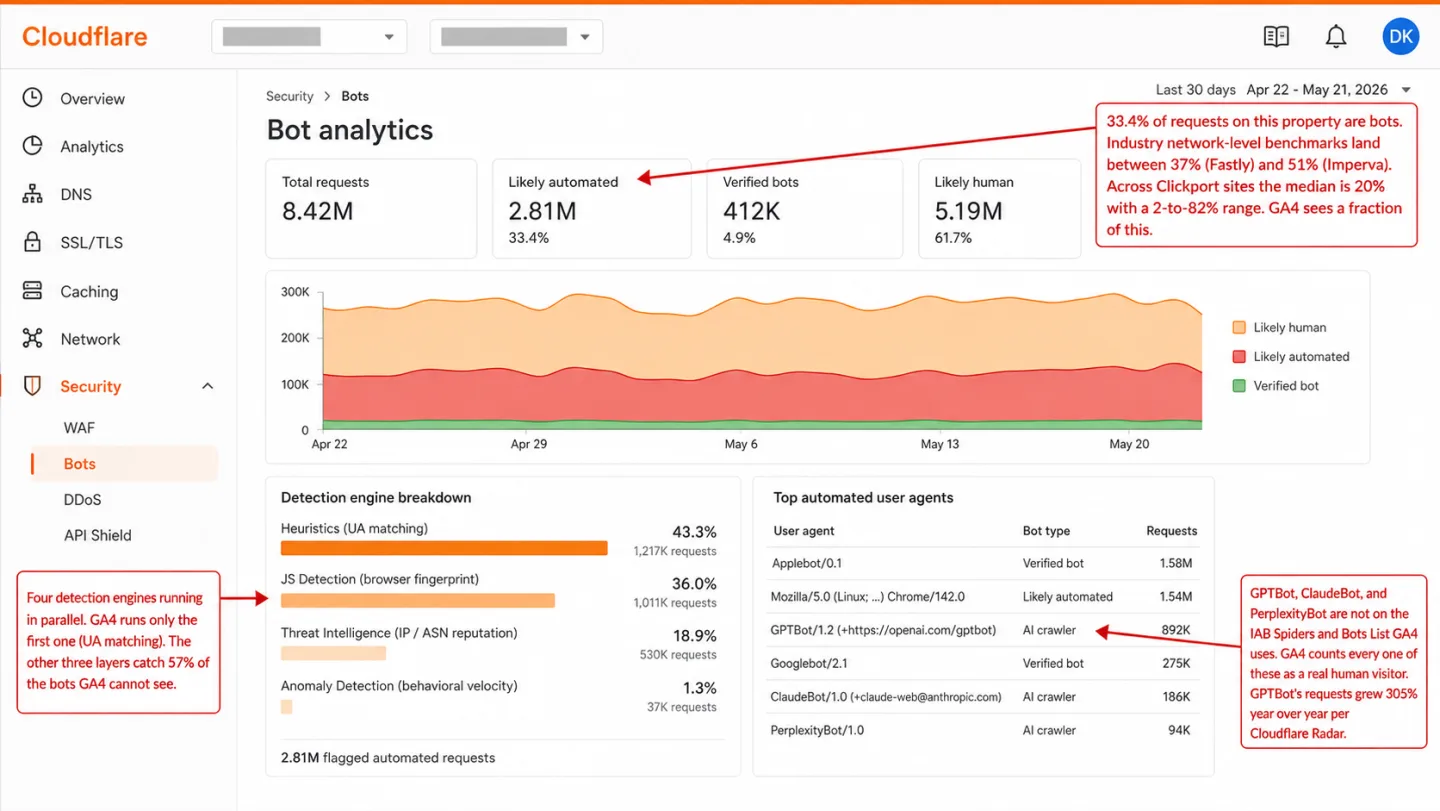
No single layer catches every bot, and I've stopped expecting one to. The thing that works is stacking layers, so each one mops up what the layer before it let through.
UA matching. Catches declared bots like Googlebot, Applebot, YandexBot by matching substrings against the IAB list or a free alternative like isbot. It fails the moment a bot spoofs a Chrome or Firefox UA. This is the whole of what GA4 does, and it's the floor, not the ceiling.
IP and ASN reputation. Catches bots running out of cloud providers like AWS, GCP, Tencent Cloud, and ColoCrossing by keeping lists of known-bad IPs and whole datacenter CIDR ranges. It fails against residential proxy networks that route bot traffic through real consumer ISPs. OWASP says it straight: IP reputation "shouldn't be used as the sole or primary defense."
Browser fingerprinting. Catches headless Chrome and automation frameworks through what the browser gives away: the GPU renderer string, the TLS handshake hash (JA3/JA4), canvas fingerprints, headers that are missing or don't line up. Cloudflare's JS Detection Engine documents this approach in public. It fails against patched anti-detect browsers like Linken Sphere and Multilogin that fake convincing GPU strings.
Behavioral analysis. Catches bots by the interaction patterns no person produces: request cadence, the randomness of mouse movement, scroll velocity, the gap between events. Cloudflare's Anomaly Detection ignores the user-agent entirely and scores each request against a domain's normal traffic. It fails against slow bots that mimic human timing on purpose, one request every 30 seconds with a bit of jitter thrown in.
| Layer | Catches | Misses |
|---|---|---|
| UA matching | Declared bots with honest UAs | Any bot spoofing a browser UA |
| IP / ASN reputation | Datacenter bots (AWS, GCP, Tencent) | Residential proxy networks |
| Browser fingerprint | Headless Chrome, Puppeteer, Playwright | Patched real-browser automation |
| Behavioral velocity | Bot farms with abnormal cadence | Slow bots with jitter |
The math is what does the work here. A bot has to beat all four layers to get counted as human. Any one layer is cheap, and any one layer can be beaten on its own. Stack them and they compound. The attacker who slips past the first is still caught by the second.
That means GA4 runs one of the four detection layers, and that's the whole reason the 57% gap exists.
What Clickport catches that GA4 doesn't
During the 30-day study, Clickport's detection ran four layers in order: UA matching, browser fingerprint (GPU and canvas), datacenter IP reputation, and behavioral velocity. I'll be honest about one of them. Partway through the window I had to turn the behavioral velocity layer down, because it started flagging a dominant real-user fingerprint as a bot, and a rebuilt version is on the way. When I measured the output, UA alone caught 43% of the bots. The other 57% needed one of the deeper layers to surface at all.
Here's how that broke down:
- UA pattern (the one GA4 can also catch): 43.3% of our detections
- Browser GPU fingerprint (SwiftShader, ANGLE renderer strings): 36.0%
- Datacenter IP reputation (AWS, Tencent Cloud, ColoCrossing, and the like): 18.9%
- Behavioral velocity (bot farms with an abnormal cadence): 1.3%
- Other fingerprint signals (no viewport, instant execution, arm64 Linux): <1%
So a GA4 user on the default bot filter sees only the green bar. Everything in red gets logged as real human traffic in their dashboard. Put another way: more than half of what I caught, GA4 would have waved through as human.
The biggest specific categories we caught over the 30 days: Applebot (1.58 million), a generic Software GPU Renderer that's headless Chrome (1.54 million), the Apple Inc. ASN (869,000, though some of that is iCloud Private Relay carrying real people), Googlebot (275,000), and ANGLE SwiftShader (135,000). In plain English: two names accounted for most of what I blocked.
Let me be clear about the limit. Clickport can't see a bot that arrives with no signal at all. A bot running a real browser from a residential IP, with human timing and a clean fingerprint, gets past everyone, us included. There's no magic here, only the signal stack. We run more layers than GA4 does, so we catch more of what GA4 misses. The bots that beat all four layers still count as humans everywhere, on this dashboard too. That means I won't promise you a clean number, only a cleaner one than GA4 hands you.
If your Direct bucket is growing and you want to see what's really inside it, do try Clickport free for 30 days. One script tag, no credit card. And if you'd rather read how the detection works before you sign up, here's the bot detection under the hood.
Frequently asked questions
Why doesn't GA4 have a native AI bot channel in 2026?
Google hasn't said. Here's what's on the record. Google files AI Overviews and AI Mode traffic under Organic Search, which fits, since both are served through google.com. An AI-assistants regex example landed in the Custom Channel Groups documentation in July 2025, but you have to set it up yourself. It isn't a default channel. Making AI a default would mean Google either picks which platforms count or matches on something beyond the referrer domain, and it has done neither.
Can I see which bots GA4 excluded?
No. Google's documentation says it flat out: "you can't see how much known bot traffic was excluded." The data is dropped before processing. No bot report, no BigQuery export, no audit of what got filtered. You get the number after the filter ran, and nothing about what it took out.
What percentage of my website traffic is normal to have as bots?
Depending on your site type and how hard you're being scraped, anywhere from 2% to 50% and up. Our own data shows a median of 20% across sites with more than 100 human events a month. The network-level benchmarks from Imperva and Akamai sit in the 37% to 51% range. That means even the clean end is rarely zero. Under 10% and you're on the clean end. Over 40% and something is actively scraping you.
How do I stop bots without blocking Google's crawlers?
Google publishes a verified list of its own crawlers with IP ranges you can check by reverse DNS. Any filtering you set up should let Googlebot, AdsBot-Google, and Googlebot-Image through. Same for Bingbot, since Microsoft publishes its IP ranges too. The whole game is blocking the bad bots without clipping the good ones, and that's why IP reputation paired with UA matching beats either signal on its own.
Does a CAPTCHA stop bot traffic in GA4?
Not in 2026, not really. A 2023 USENIX paper from UC Irvine and Microsoft found that bots solve distorted-text CAPTCHAs in under a second with close to 100% accuracy. People take up to 15 seconds and get it right only 50-84% of the time. That means the test is now harder for the human than for the machine. On image-based CAPTCHAs like reCAPTCHA grids and hCaptcha, bots and people finish in roughly the same time. A CAPTCHA is a speed bump, not a shield. It trims the low-effort bots and lets the ones with ML solvers walk straight through.
Why do I have traffic from countries I don't sell to?
Three usual suspects. One, scrapers running on cheap cloud compute in regions like Singapore, Brazil, and Vietnam. Two, referrer spam and scripted traffic that hits every domain it can reach. Three, residential proxies rotating through consumer IPs in a string of countries. Filter your Explorations by country and lay it next to your mobile/desktop split. The suspect countries almost always show up with a desktop skew and engagement near the floor.
Does server-side tracking solve the bot problem?
No. Server-side tracking fixes other things, like consent blocks and ad-blocker interference, but the bot request still reaches your server. If the bot's user-agent reads like a real browser and its IP is a residential proxy, your server-side pipeline has just as much trouble telling it from a human as a client-side tag does. Bot detection has to happen while you process the request, not in the layer that ships the data.
One line to take away
Your analytics is counting things that aren't people. The filter you trust to stop that is checking user-agent strings against a paid list. More than half of real bots never show up on it. The gap isn't small, and it keeps growing as AI crawlers, residential proxies, and headless browsers get cheaper to run. So whatever number your dashboard showed for last month, the real count of humans is smaller. How much smaller comes down to which signals you decide to look at.

Comments
Loading comments...
Leave a comment