How Bot Detection Actually Works in Web Analytics (2026)
Show article contentsHide article contents
- What is bot detection in web analytics?
- Half of your traffic is not human
- What GA4 actually does about bots
- Why every other analytics tool is a black box too
- The 7 layers a bot must survive
- 11 detection checks, explained
- Behavioral scoring: catching bots that pass every other check
- 56 AI bots, three intent categories
- The Bot Center: seeing what others hide
- What we are building next
- The math behind dirty data
- Start with clean data
- FAQ
Google Analytics filters bots with a single list of user-agent strings. If the bot says "I'm Googlebot," GA4 drops it. If the bot says "I'm Chrome 124 on Windows 11," GA4 logs a real person. That is the whole system. One list. No behavioral analysis. No IP checks. No transparency. And it runs on 28 million websites. Bot detection decides how much you can trust a tool, right alongside the privacy and accuracy story in our privacy-friendly analytics guide. Here is how it really works, and where almost every tool gets it wrong.
- GA4's bot filter uses a single list (IAB/ABC) that only catches self-identifying bots. In controlled tests, it filtered zero bot sessions that used standard browser user-agents.
- 51% of all web traffic in 2024 was automated, with bad bots alone at 37%. AI scraper traffic grew 300% year-over-year. Only 2.8% of websites are fully protected.
- Clickport runs 11 detection checks across 7 filtering layers at ingestion time, from tracker-side hard stops to fingerprint velocity analysis. Blocked events never reach the database.
- No other analytics tool shows what it blocks. Clickport's Bot Center displays blocked counts by detection method, top sources, AI bot breakdown by intent, and blocklist update status.
- Behavioral scoring using Welford's online variance algorithm detects bots that pass all other checks by analyzing mouse velocity, scroll patterns, and timing distributions in O(1) memory.
What is bot detection in web analytics?
Bot detection in web analytics is the work of catching non-human traffic before it dirties your data. Bots inflate session counts. They spike bounce rates, skew engagement, and quietly poison every decision you make off those numbers. Good detection mixes behavioral analysis, device fingerprinting, IP reputation, and JavaScript environment checks to split machines from people before either one reaches a report.
Common signals analytics tools use to identify bots:
- Zero-engagement sessions. Sessions with 0-second engagement time, single-page visits, no scroll, no clicks. Bots rarely trigger interaction events.
- Unusual traffic patterns. Sudden high-volume spikes (especially direct), abrupt drops in organic, traffic that does not match your usual rhythm.
- Geographic anomalies. Surges from countries that do not match your audience.
- Datacenter IP origin. Traffic from AWS, Google Cloud, Azure, OVH, Hetzner ranges. Real visitors browse from residential ISPs.
- Source/medium check. Known AI crawlers and spam referrers, traffic from sources that do not match your marketing footprint.
Common bot detection methods:
- Behavioral monitoring. Mouse velocity, scroll patterns, click timing, dwell distributions. Bots show inhuman precision or impossible speed.
- Device fingerprinting. Browser settings, plugin sets, screen resolution, WebGL renderer. Headless browsers leak signals real Chrome does not.
- IP reputation and threat intelligence. Match against known datacenter, VPN, and botnet IP databases.
- JavaScript and cookie challenges. Many bots cannot execute JS or accept cookies; tools that require both filter a chunk by default.
- Rate limiting. Request volume per second beyond what humans can produce.
GA4 does almost none of this. It uses one sliver of IP reputation: its own IAB/ABC list of self-identifying bots. That is the whole defense. The rest of this article shows what real bot detection looks like, where each layer breaks, and why most tools pick silence over showing their work.
Half of your traffic is not human
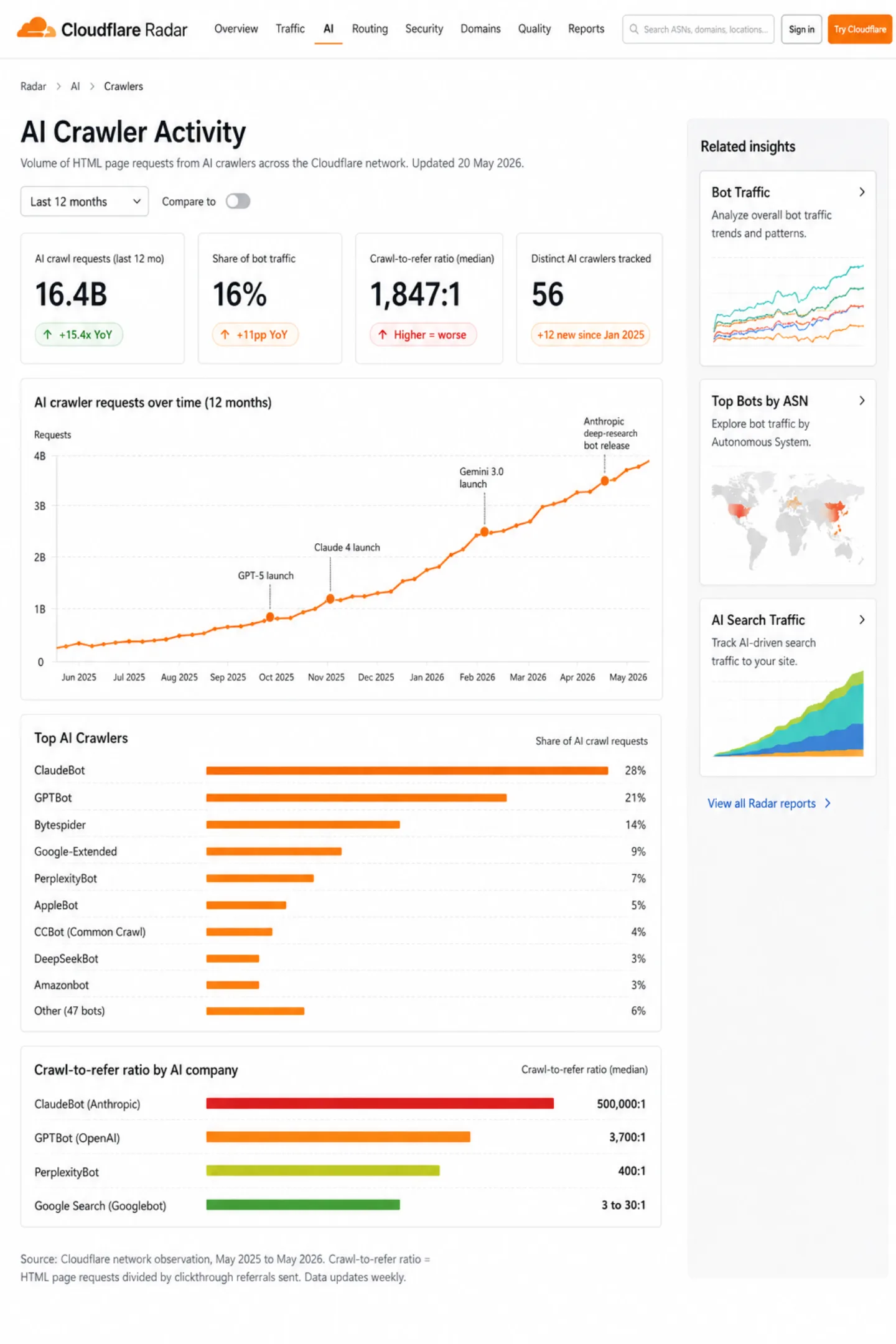
In 2024, machines started to outnumber people on the web. The Imperva 2025 Bad Bot Report, drawn from traffic across their global network, found bots now make up 51% of all web traffic. Read that again. More than half of everything hitting your site is not a person. Bad bots on their own are 37% of it, up from 32% in 2023. The number has climbed six years running.
This is not some fringe corner of the web. Imperva blocked 13 trillion bad bot requests in 2024. Akamai reported AI scraper traffic tripling in a single year, a 300% jump. Cloudflare's 2025 data shows non-AI bots driving 50% of all HTML page requests, 7% more than humans manage.
Cloudflare CEO Matthew Prince put it bluntly at SXSW in March 2026: "We suspect that, in 2027, the amount of bot traffic online will exceed the amount of human traffic."
AI is what poured fuel on the fire. DoubleVerify found general invalid traffic jumping 86% year over year in the second half of 2024, with AI scrapers like GPTBot, ClaudeBot, and AppleBot behind 16% of known-bot impressions. The scale is hard to picture until you look at one site's logs. Barracuda's research found one web application took 9.7 million AI scraper requests in 30 days. Another took more than 500,000 in a single day.
So here is the catch. If your analytics tool cannot tell a bot from a real visitor, every number in your dashboard is a guess. Your traffic is inflated. Your engagement rates are watered down. Your A/B tests are contaminated. And your marketing budget gets spent against numbers that are part fiction.
What GA4 actually does about bots
Google Analytics 4 leans on one mechanism for bot detection: the IAB/ABC International Spiders and Bots List. It is a hand-kept list of known bot user-agent strings and IP addresses, maintained by the Interactive Advertising Bureau and refreshed about once a month.
Google's own documentation says that "traffic from known bots and spiders is automatically excluded." The whole thing hinges on that one word, known. If a bot tells GA4 it is Googlebot or Bingbot in its User-Agent header, GA4 drops it. If that same bot sets its user-agent to "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36," GA4 logs a real person on Windows.
That is the detection system. One list. The whole thing rests on the bot being polite enough to confess.
☐ Datacenter IP blocking
☐ JavaScript environment signals
☐ Behavioral scoring
☐ Spam referrer filtering
☐ Fingerprint velocity
☐ Rate limiting
☐ Blocked traffic dashboard
☑ 3,400+ datacenter IP ranges
☑ 4 JavaScript environment checks
☑ Behavioral scoring (Welford's)
☑ 2,342 spam referrer domains
☑ Fingerprint velocity analysis
☑ Per-IP rate limiting (60/min)
☑ Bot Center with full breakdown
The fallout is easy to measure. Plausible ran controlled tests, sending bot traffic to both GA4 and their own tool. Bots wearing non-human user-agents: GA4 logged 22 pageviews. Bots wearing normal Chrome user-agents: GA4 logged 40 pageviews. Bots coming from datacenter IPs: GA4 logged 17 pageviews. I ran my own test with 1,000 Puppeteer bot sessions. GA4 caught none of them. Zero. In a separate 30-day study across the sites we measure, 57% of the bots we detected would have walked straight past GA4's default filter, because catching them needed signals GA4 never looks at.
Then comes the part that makes it permanent. GA4 cannot go back and pull bot traffic out of reports it has already processed. Google's data deletion feature works on parameter values, not on what kind of traffic something was. Once bot sessions land in your GA4 property, they live there forever. Your history stays inflated.
Why every other analytics tool is a black box too
The privacy-focused tools handle bots better than GA4. Most of them are built by people who care about this. But they all share one habit: they tell you nothing about what they block.
Plausible uses UA pattern matching, roughly 32,000 datacenter IP ranges, and referrer spam filtering. They have blocked around 2 billion bots across all subscribers since February 2023. That is a lot of bots stopped. None of it shows up in the dashboard. No blocked counts, no breakdown by method, no way to see what got filtered.
Fathom is blunt about it: "We're not going to detail what we've changed in our bot detection algorithm." They treat the method as a trade secret. You see clean numbers and you are asked to trust that they are clean.
Matomo goes furthest of the older tools, with a TrackingSpamPrevention plugin that covers cloud provider IPs and headless browser detection. The catch is that these are opt-in plugins, off until you turn them on. And the third-party BotTracker plugin logs bot visits, which is not the same as a real detection dashboard.
Umami, the open-source favorite, runs on one npm library (isbot) for user-agent matching. No IP detection. No behavioral analysis. No referrer spam filtering. When Umami spots a bot, it answers {"beep": "boop"} and gets on with its day.
| Feature | GA4 | Plausible | Fathom | Matomo | Clickport |
|---|---|---|---|---|---|
| Shows blocked counts | No | No | No | Plugin | Yes |
| Breakdown by method | No | No | No | No | Yes |
| AI bot categorization | No | No | No | No | Yes |
| Manual session flagging | No | No | No | No | Yes |
| Blocklist update status | No | No | No | No | Yes |
The whole industry treats bot detection as a checkbox. "Bot filtering: enabled." That is as far as it goes. No method shared, no blocked traffic shown, no detection rates put on the record. You are asked to hand a black box the accuracy of every number you make decisions on.
If you have ever stared at your analytics and thought these numbers don't feel right, this is most likely why. We took the other road: we show you exactly what we block and why.
The 7 layers a bot must survive
Every event that reaches Clickport runs through seven separate filtering layers before it can show up in your dashboard. Any layer can throw the event out. Rejected events never reach the database.
This is filtering at ingestion time, not at query time, and the difference is the whole game. GA4 collects everything and filters later, when it builds a report. We block confirmed bots before we write a single row. Your database is clean from day one. Nothing to clean up after the fact. No history quietly inflated for the rest of its life.
We also built a safety net for the in-between cases. Bots we are sure about get blocked at ingestion. Suspicious sessions that slip through can be flagged by hand in the Sessions panel, which pulls them out of every dashboard query without touching the underlying data.
The pipeline is built around one idea from the bot detection research world: cost asymmetry. No single layer has to be unbeatable. It only has to make getting past it more expensive. A bot can spoof a user-agent for free. It can pay a little to rent residential proxies. It can patch navigator.webdriver cheaply. Doing all of that at once, every time, across thousands of requests, while also faking the timing of a real human, gets expensive fast. That is the point. You do not need a perfect wall. You need to make cheating cost more than it is worth.
11 detection checks, explained
Layer 3 runs 11 checks in priority order. It stops at the first match: the moment one check confirms a bot, the rest are skipped. Every blocked event keeps a record of the method that caught it and the exact detail, which bot name, which IP range, which behavioral signal.
Environment signals (checks 1-4)
These read signals the tracker's JavaScript picks up while running in the visitor's browser.
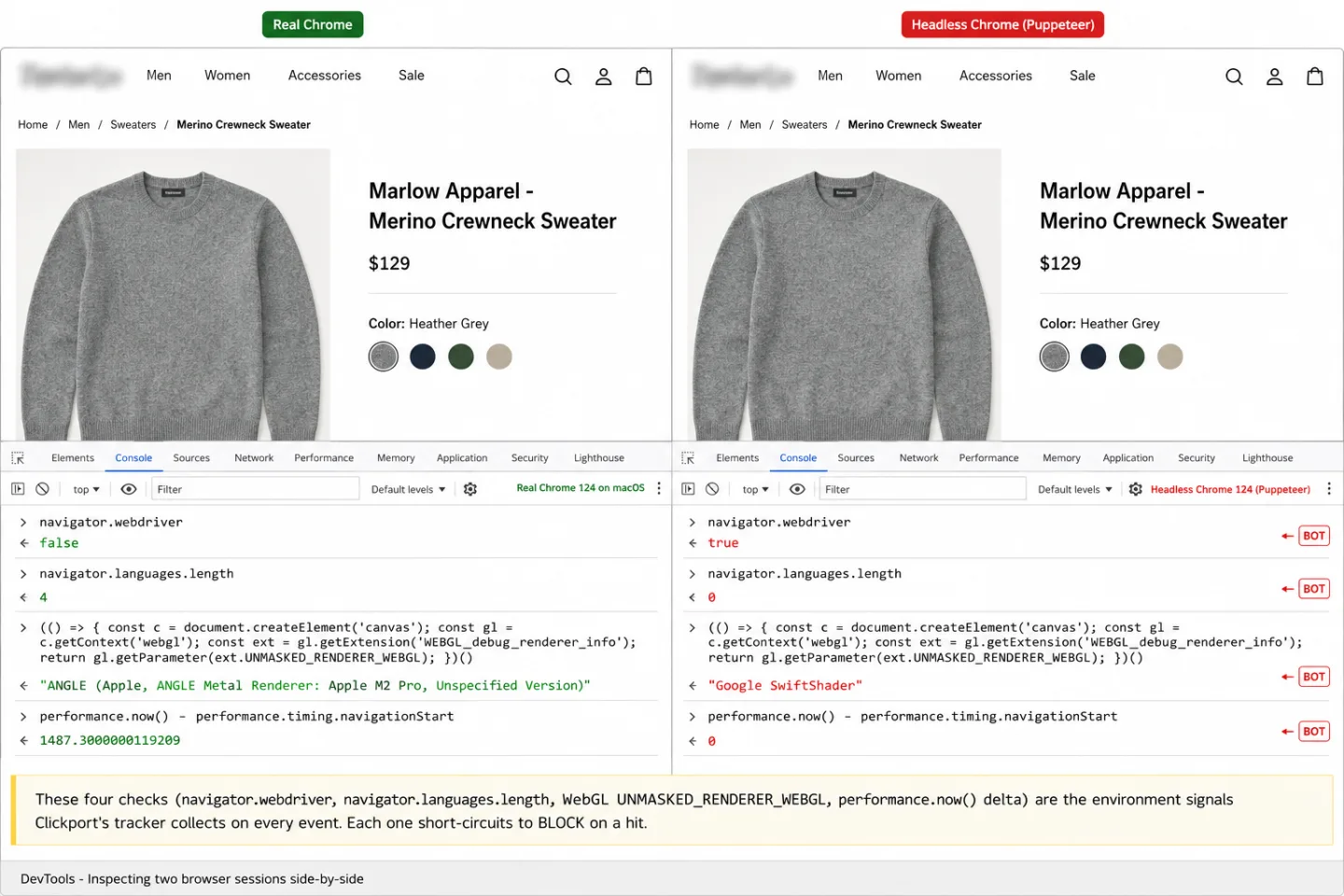
Check 1: Webdriver flag. The W3C WebDriver specification tells browsers to set navigator.webdriver = true when an automation tool like Selenium, Playwright, or Puppeteer is at the wheel. Real browsers return false. The tracker reads this at startup and sends it with every event.
Check 2: Language count. The tracker reads navigator.languages.length. Real browsers always report at least one language. A count of zero means the browser was never set up properly, and that only happens in automation.
Check 3: Software GPU. The tracker reads the WebGL renderer string via UNMASKED_RENDERER_WEBGL. Real browsers name a real GPU, like "ANGLE (NVIDIA GeForce RTX 3080)". Headless Chrome and CI machines fall back to software renderers: SwiftShader or llvmpipe. Those are well-documented headless tells.
Check 4: Instant execution. The tracker times the gap between when the script starts and when it sends its first event, using performance.now(). A gap of zero milliseconds means the script ran the instant it loaded, which no real page does. Only automation that skips realistic page loading behaves that way.
Network signals (checks 5-8)
These read server-side data that comes with the HTTP request.
Check 5: Empty user-agent. A missing or empty User-Agent header. Real browsers always send one.
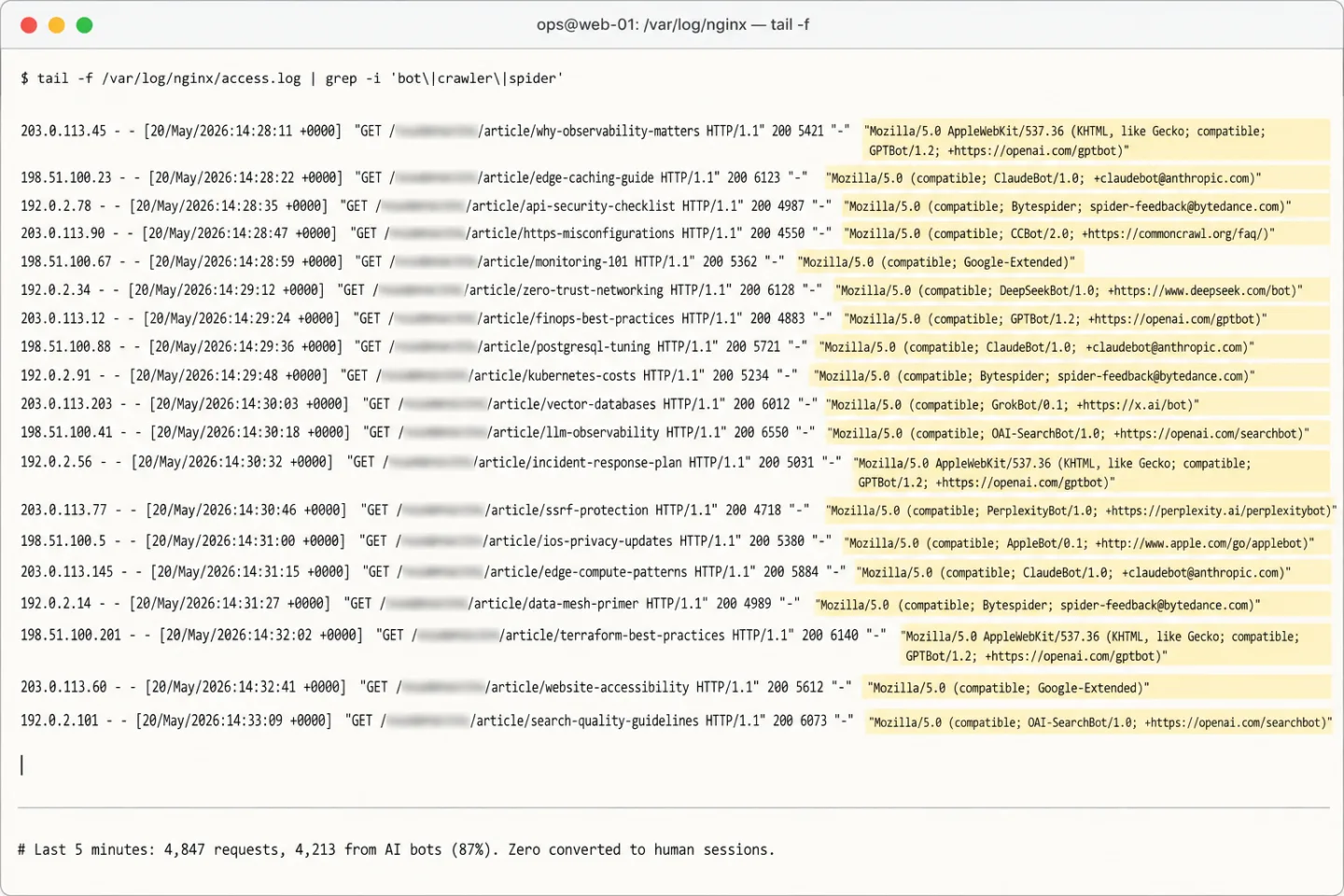
Check 6: User-agent pattern matching. A regex that matches over 100 known bot patterns across 8 categories: AI bots (54 patterns), search engines (15), SEO tools (10), social crawlers (9), monitoring services (10), feed readers (5), HTTP libraries and headless browsers (11), and vulnerability scanners (6). This is the same idea GA4 uses with the IAB list. The difference is that we keep our own patterns and update them weekly, not monthly.
Check 7: Datacenter IP blocking. The client IP is checked against 3,434 datacenter IP ranges from the ipcat project plus 5 ranges we hardcode (Apple, Tencent Cloud, Huawei Cloud, Google Crawlers). The lookup uses binary search over sorted ranges, so it takes 12 comparisons in the worst case instead of 4,000.
Here is the part that trips up most naive blocking. Block every datacenter IP and you also block real people on corporate VPNs and commercial VPN services, because providers like NordVPN and ExpressVPN run their exit nodes on cloud infrastructure. A developer working through their company's AWS-hosted VPN is a person, not a bot.
So we keep a VPN whitelist: 10,700+ CIDR ranges from the X4BNet VPN list. If an IP shows up on both the datacenter blocklist and the VPN whitelist, we treat it as a real visitor. That solves the false positive that makes blunt IP blocking untrustworthy.
Check 8: Spam referrer filtering. The referrer hostname is checked against 2,342 known spam domains from the Matomo referrer-spam-list. Referrer spam is an old trick: bots send fake requests with a spoofed Referer header pointing at a spam site, hoping to earn a backlink or lure a curious webmaster into clicking through.
Behavioral signals (checks 9-11)
These catch the bots that sail past every environment and network check.
Check 9: No viewport. A screen width of zero on an event that is not a pageleave. Real browsers always report a viewport size.
Check 10: ARM64 Linux. User-agents that carry Linux aarch64 or Linux arm64. That is server and container hardware (AWS Graviton, Docker on ARM). Nobody browses the web from an ARM64 Linux server.
Check 11: Impossible interaction patterns. This one fires on a pageleave where scroll depth is 90% or higher, engagement time sits between 0 and 5 seconds, and there was not a single mouse or keyboard event. Scrolling through 90% of a page in under 5 seconds while touching nothing is something no human can do.
All three blocklists, the datacenter IPs, the VPN ranges, and the spam referrers, refresh on their own every week. A status file logs the count and the last-update time for each one. If a fetch fails, the system keeps using the older cached list instead of running with no protection at all.
Behavioral scoring: catching bots that pass every other check
The 11 checks catch most bot traffic. But what about a bot running a real Chromium browser on a residential proxy with a spoofed user-agent? It passes every environment check, because it is a real browser. It passes the datacenter IP check, because it sits on a residential IP. It passes the spam referrer check, because it carries no referrer. On paper it looks human.
This is where behavioral scoring earns its keep. The tracker watches mouse movement, scroll behavior, and timing, then works out a behavior score from 0 to 100 using Welford's online variance algorithm.
The algorithm is lovely in how little it needs. It tracks running mean and variance in a single pass with O(1) memory: no arrays, no history kept around. Each new data point nudges three values (count, mean, M2), and the coefficient of variation falls out of those three at any moment you ask for it.
What the score measures
Mouse velocity CV (35 points possible). The tracker samples mousemove events and works out the distance and time between them. After 5 or more samples, it figures the coefficient of variation. Real people have wildly uneven mouse speed (CV > 0.3) because they pause, speed up, overshoot, and correct. Bots glide at a constant speed or in mechanical lines (CV < 0.1).
Scroll velocity CV (25 points possible). The same idea, pointed at scroll events. After 3 or more samples, it measures the variance. Real people scroll in ragged bursts, stopping to read. Bots scroll at one even speed.
Timing bucket distribution (25 points possible). After 10 or more mouse events, the tracker drops the gaps between them into three buckets: under 20ms, 20-100ms, and over 100ms. Real people spread across all three, with no single bucket over 50%. Bots pile into one bucket, because their timing is too regular to be human.
Presence bonus (15 points). Any mouse movement at all earns 15 points. Plenty of bots never move the mouse once.
Irregular scroll patterns
Spread timing distribution
Natural pauses and corrections
Partial mouse/scroll data
Short session duration
May be mobile or keyboard user
Constant-speed scrolling
Mechanical timing patterns
Zero interaction events
Right now the behavior score is collected and shown in the Bot Center's traffic quality section. We do not yet use it to block on its own, and the reason is honesty: behavioral scoring carries more false-positive risk than the hard signals. A keyboard-only user who never touches the mouse would score low even though they are perfectly human, and blocking that person would be worse than letting a bot through. So we are building toward a composite score that weighs the behavioral data alongside the other 11 checks instead of treating it as a yes-or-no switch.
56 AI bots, three intent categories
AI crawlers are the fastest-growing slice of bot traffic. Cloudflare observed AI "user action" crawling shooting up more than 15x year over year in 2025. But not every AI bot wants the same thing, and lumping them together is a mistake.
We track 56 AI bots across three intent groups: 15 live retrieval, 14 search indexing, and 24 model training, plus 3 old legacy entries we keep for reference. The split matters, because what you should do about each one is different.
Live Retrieval (15 bots)
These bots fetch a page in the middle of a live AI conversation. Someone asks ChatGPT to "look up the pricing on this website," and ChatGPT-User goes and reads your page. That is real human intent. A person wants your content right now.
Examples: ChatGPT-User (OpenAI), Claude-User (Anthropic), Perplexity-User, meta-externalfetcher (Meta), Google-Agent, kagi-fetcher.
Search Indexing (14 bots)
These crawl your site to build an AI-powered search index. Think of them as Googlebot for the AI era. Getting indexed by them means your content can turn up inside AI-generated answers.
Examples: OAI-SearchBot, Claude-SearchBot, PerplexityBot, Amazonbot, meta-webindexer, PhindBot, DuckAssistBot.
Model Training (24 bots)
These scrape your content in bulk to train large language models. They give your site nothing back. No referral traffic, no user intent, just server load and bandwidth on your bill.
Examples: GPTBot (OpenAI), ClaudeBot (Anthropic), Bytespider (ByteDance), Google-Extended, CCBot (Common Crawl), DeepSeekBot, GrokBot (xAI).
The crawl-to-refer ratio tells the whole story. Google Search crawls 3 to 30 pages for every visit it sends back. That is a fair trade. ClaudeBot crawls 500,000 pages for every visit. That is not a partnership. That is your bandwidth being mined.
The Bot Center splits AI bot traffic by intent group, so you can see which AI companies are reading your content, how often, and whether any of them send a visitor back. You can also track AI search referral traffic on its own in your sources panel, to measure what it is really worth to you.
The Bot Center: seeing what others hide
Most analytics tools treat bot filtering as plumbing in the wall. It happens out of sight. You never see it, you never question it, and you never find out whether it is working.
We built the Bot Center to put bot detection in plain view.
It shows total blocked events by detection method, so you can see how many were caught by UA pattern matching against datacenter IP blocking against behavioral signals. It shows the top blocked sources, the specific bots and IP ranges hammering your site hardest. It shows AI bot traffic split by intent group. It shows traffic quality drawn from the behavior scores. And it shows when each blocklist last updated, so you know your protection is current.
The Sessions panel gives you a second layer of control by hand. You can open any session, read its engagement metrics (duration, scroll depth, pages viewed, interaction count), and flag a suspicious one as a bot yourself. Flagged sessions drop out of every dashboard query but stay in the database, so you can always check your own work.
That is the hybrid: automatic blocking at ingestion for the bots we are sure about, manual control at the session level for the ones we are not. Your data is clean by default, and you hold the tools to make it cleaner.
Rahul Gupta, Senior Principal Software Engineer at Barracuda, put it plainly: "Their presence can distort website analytics leading to misleading insights and impaired decision-making." The only question left is whether your tool lets you see that distortion or buries it behind a checkbox.
What we are building next
Bot detection is an arms race. The bots keep getting smarter, so the detection has to keep moving too. Here is what is coming to our pipeline.
Tier 1 (next releases)
Deferred pageview confirmation. A 2.5-second tracker beacon that waits for any mouse, scroll, touch, or keyboard event before it confirms the visit. No event, no confirmation, and the session gets flagged. This catches the bot that fires one pageview and vanishes without touching anything.
Session timeout sweep. When a session falls out of the cache with exactly one event, no pageleave, and zero engagement, we flag it as suspicious. A lot of bots hit one page and never come back.
Client Hints header validation. Modern Chromium browsers send sec-ch-ua and sec-ch-ua-mobile headers on their own. A request that claims to be Chrome 124 in its User-Agent but forgets to bring those headers is suspicious on its face. This catches bots built on HTTP libraries with a spoofed user-agent and no real browser engine underneath.
requestAnimationFrame timing probe. A 5-frame rAF probe that spots headless Chrome by its odd frame timing. Real browsers lock to the display's refresh rate (about 16.67ms at 60Hz) with a little natural jitter. Headless Chrome either fires too fast or lands on intervals too neat to be real.
IP subnet clustering. Count unique IPs per /24 subnet per site. When 30 or more unique IPs from one /24 subnet hit a site inside 60 minutes, that is a residential proxy pool, not 30 separate people who all happen to live on the same street.
Tier 2 (planned)
Composite bot scoring. Swap the yes-or-no call on soft signals for a weighted point system. Hard signals (webdriver, datacenter IP) stay instant blocks. Soft signals (a low behavior score, odd timing, unusual geography) add points. A session piles up points across several weak tells until it crosses a line. This catches the bot that is a little off in many ways instead of badly wrong in one.
Geographic anomaly scoring. Catch language and timezone mismatches and tight geographic clustering, weighed together with engagement. Someone claiming to be in Germany with a Chinese language preference, zero scroll depth, and a 2-second session is far more suspicious than any one of those signals on its own.
Tier 3 (research)
TLS fingerprinting (JA4). A Python requests library, a Go net/http client, and a real Chrome browser each leave a different TLS fingerprint, even when the User-Agent header is spoofed. TLS fingerprinting catches the gap between what a bot says it is and what its network stack quietly admits. This one needs changes at the reverse proxy, not in application code.
Session timeout sweep
Client Hints validation
rAF timing probe
IP subnet clustering
Geographic anomaly scoring
Canvas hash clustering
MaxMind Anonymous IP DB
IPQualityScore API lookups
I will be straight about what we cannot catch today. A bot on a residential proxy, running fully instrumented headless Chrome with realistic behavior faked on top, will slip past most client-side analytics tools, ours included. No analytics-grade detection catches everything, and anyone who tells you otherwise is selling. The goal is to catch the 95% that is catchable and hand you the tools to spot the rest.
The math behind dirty data
Bot traffic does more than pad your visitor count. It bleeds into every metric in your dashboard at once.
Take a site with 10,000 real monthly visitors and a 3.5% conversion rate. That is 350 conversions a month. Now pour in 30% bot traffic, which is a careful estimate given CHEQ's finding that 17.9% of all observed traffic is fake and DataDome's report that only 2.8% of websites are fully protected.
Now your dashboard reads 13,000 visitors and the same 350 conversions. Your conversion rate shows 2.7%, not 3.5%. You just handed 23% of your apparent conversion rate to visitors who do not exist. Run paid ads off that and you are chasing a 2.7% target when reality already sits at 3.5%. Meta Ads bot traffic is the dearest version of this, because every bot click you paid for then turns around and wrecks the conversion rate in your reports.
Some channels get hit harder than others. CHEQ found that 22.1% of "direct" traffic is fake, the worst invalid rate of any channel. A sudden Direct spike is usually the first hint a site owner gets that something is poisoning their data. Bot sessions average 0.5 seconds of engagement against 43 seconds for a human. They drag your average engagement down, push your bounce rate up, and muddy the signal in every number you steer by.
A/B testing is hit hardest of all. Peakhour documented that 40% of their customers' test traffic came from bots, quietly bending the results. When bots land on Variant A and Variant B at different rates, they create a sample ratio mismatch that can flip statistical significance, and you ship the worse version believing it won.
The money side is brutal. Juniper Research projects digital ad fraud reaching $172 billion a year by 2028. Forrester found that 21 cents of every media dollar is wasted on poor data quality, which works out to $16.5 million a year for an enterprise.
Clean data is not a nice extra. It is the line between optimizing for what is real and optimizing for what is made up.
Start with clean data
Every number in your dashboard hangs on one question: was this visitor real?
If your tool cannot answer that with confidence, and cannot show you the evidence, then every decision you make off that data carries a risk you cannot even measure.
Clickport runs 11 detection checks across 7 filtering layers. Blocked events never reach your database. The Bot Center shows you exactly what was caught, how, and what is still trying to get in. You can open any session and flag anything that smells wrong. And we tell you what we cannot catch yet, with a public roadmap of what is coming.
We do all of it without cookies, without fingerprinting your visitors, and without a consent banner. Bot detection should protect your data quality without selling out the people who came to read your site.
If that sounds like the kind of analytics you want, do try it. Start your free 30-day trial. You will see your real traffic in 60 seconds, no credit card required.
FAQ
What are the main methods of bot detection?
Five categories cover almost everything you will meet in practice. Behavioral monitoring (mouse velocity, scroll patterns, click timing). Device fingerprinting (browser settings, plugin sets, WebGL renderer, screen resolution). IP reputation and threat intelligence (matching against datacenter, VPN, and botnet IP databases). JavaScript and cookie challenges (many bots cannot run JS or take cookies). Rate limiting (more requests per second than a person could send). The good systems use all five and weigh the results together, because no single signal catches every bot.
How do I know if my analytics data includes bot traffic?
If you run GA4 with nothing else on top, your data almost certainly carries bot traffic. The Imperva 2025 Bad Bot Report found that 51% of all web traffic is automated. The tells: spikes from datacenter locations (Ashburn, Virginia turns up a lot), sessions with zero engagement time, bounce rates that look too high, and traffic from places that have nothing to do with your audience.
Does GA4 automatically filter bots?
GA4 drops traffic from bots that name themselves on the IAB/ABC International Spiders and Bots List. That catches search engine crawlers like Googlebot and Bingbot. It does not catch bots wearing a standard browser user-agent, bots from datacenter IPs, or headless browsers like Puppeteer. In controlled tests, GA4 filtered zero bot sessions that used real browser user-agents.
How do I enable bot filtering in GA4?
You cannot turn it off and you cannot tune it. GA4's IAB/ABC bot filter runs by default on every property, and there is no setting to switch it on, off, or anywhere in between. The only knobs you really get are Data Filters (under Admin > Data Settings > Data Filters), where you can exclude internal traffic by IP, and Referral Exclusion Lists, where you can drop spam referrers. Neither one is real bot detection. If your aim is keeping bots out of your reports, GA4's built-in filter is about the floor of what you can do. Everything past that means a different analytics tool, server-side filtering, or a separate bot management product.
Can bots execute JavaScript?
Yes. Modern headless browsers (Puppeteer, Playwright, Selenium) run JavaScript in full, analytics scripts like GA4's gtag.js included. The old comfort that JavaScript-based tracking filters bots on its own stopped being true a long time ago. Clickport's tracker reads environment signals (WebGL renderer, language count, execution timing) that split real browsers from automated ones, which catches headless browsers that run the JavaScript but cannot fake a full browser environment behind it.
What percentage of web traffic is bots in 2026?
Going by the most recent broad studies: 51% of all web traffic is automated (Imperva 2025), with bad bots on their own at 37%. AI scraper traffic tripled in a year, up 300% (Akamai 2025). The DataDome 2025 report found only 2.8% of websites are fully protected from bot traffic, down from 8.4% in 2024. Cloudflare's CEO expects bot traffic to pass human traffic by 2027.
How does bot detection work without cookies or fingerprinting?
Clickport's bot detection works on signals that never identify a single person: IP range matching against known datacenter providers, user-agent pattern matching, JavaScript environment checks (WebGL renderer, execution timing), and behavioral analysis in aggregate. The behavior score is variance math on mouse and scroll velocity, not tracking of any one user. IP addresses are used for detection at ingestion time and then never written to the analytics database. No cookies get set. No one is followed from site to site.
Can I retroactively remove bot traffic from my analytics?
In GA4, not really. Its data deletion feature works on parameter values, not on what kind of traffic something was. Once bot traffic is processed, it stains your historical reports for good. In Clickport, bot traffic is blocked at ingestion and never reaches the database, so there is nothing left to remove. For the sessions that slip through, you can flag them as bots by hand from the Sessions panel, which pulls them out of every dashboard query.
What about bots on residential proxies?
Residential proxy networks (like Bright Data or Oxylabs) route bot traffic through real consumer IP addresses, which slides right past datacenter IP detection. This is the hardest category there is. We go after it with behavioral scoring (residential proxy bots still tend to move in non-human ways), fingerprint velocity analysis (spotting clusters of identical browser fingerprints spread across many IPs), and the planned IP subnet clustering feature. No client-side analytics tool catches every residential proxy bot, and I would rather say that out loud than pretend otherwise.
How often are the blocklists updated?
Clickport's three external blocklists (datacenter IPs, VPN whitelist, spam referrers) refresh weekly through an automated script. Cloud providers like AWS, Google Cloud, and Azure hand out new IP ranges all the time, so a weekly update is what it takes to keep up. The blocklist status, the count and last-update time for each list, is right there in the Bot Center.

Comments
Loading comments...
Leave a comment